
In the rapidly changing world of generative AI, vector databases have taken a center stage for any enterprise generative ai solution. Tailored for high dimensional data efficient for data storage and retrieval mechanisms, they play a crucial role in the world of AI and machine learning.
Understanding Vector Databases
So what exactly are vector databases? Think of them as data warehouses specifically designed for high-dimensional vectors. These vectors are like mathematical fingerprints, capturing the essence of your data – text, images, or even sensor readings – in a multi-dimensional space. Each dimension represents a specific feature or characteristic.
Let’s understand this by a simple example. Imagine you have a giant room filled with books. A traditional database would be like a card catalog, letting you find books by title or author. But a vector database is more like a mind map. It connects books based on ideas and themes, allowing for lightning-fast searches based on content and meaning.
Technical Architecture of Vector Databases
Now one would think how a Vector database actually works. Let’s dissect the technical architecture of vector databases to unravel their inner workings. At a fundamental level, they comprise two key components:
- Storage layer: This layer is responsible for efficiently storing and indexing the high-dimensional vectors. It leverages specialized data structures such as inverted indexes, tree-based structures (e.g., KD-trees), or state-of-the-art techniques like Product Quantization to optimise storage and retrieval operations.
- Embedding: We transform raw data (text, images) into vectors using machine learning techniques. Imagine a complex algorithm summarising a book into a series of key points.
- Indexing: The vectors are then stored and meticulously indexed within the database. This is where the magic happens – the database structures the data for efficient retrieval.
- Query engine: The query engine facilitates fast and accurate similarity search within the vector space. It employs algorithms like Approximate Nearest Neighbor (ANN) search techniques, leveraging indexing structures to efficiently locate vectors that are close in proximity to a given query vector.
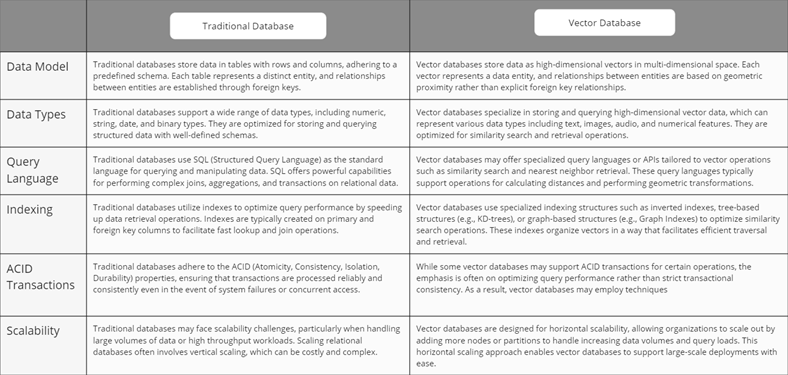
Traditional vs Vector Database
Now let’s understand how traditional relational database differs a vector database through key features.
Vector Database – Empowering Gen AI
Vector databases play a pivotal role in enabling the functionality and efficiency of Generative AI (Gen AI) solutions. Let’s go through them:
- High-dimensional storage: Gen AI models often operate in high-dimensional spaces, requiring efficient storage and retrieval of complex data representations. Vector databases excel in storing and organizing high-dimensional vectors, enabling seamless manipulation and analysis within the multi-dimensional space.
- GPU acceleration: Leveraging the computational power of GPUs can significantly accelerate similarity search and other vector operations. Vector databases offer GPU acceleration, enabling Gen AI models to achieve breakthrough performance and efficiency.
- Efficient similarity search: One of the core functionalities of vector databases is their ability to perform fast and accurate similarity searches within the vector space. This feature is crucial for Gen AI models to identify and retrieve semantically similar data entities, facilitating tasks such as content recommendation and semantic understanding.
- Scalability: As Gen AI solutions scale to handle ever-growing datasets and user interactions, scalability becomes a critical factor. Vector databases are designed to scale horizontally, allowing for seamless expansion across distributed clusters without compromising performance or reliability. This scalability ensures that Gen AI models can continue to operate efficiently, even as the volume of data grows exponentially.
- Real-time updates: In dynamic environments where data is constantly changing, real-time updates are essential for maintaining the accuracy and relevance of Gen AI models. Vector databases support efficient real-time updates, enabling models to adapt and learn from new data on the fly.
- Support for complex data types: Gen AI models often work with diverse data types, ranging from text and images to audio and video. Vector databases offer robust support for storing and querying complex data types, allowing models to leverage rich representations of multimedia content.
- Integration with AI frameworks: To streamline the development and deployment of Gen AI solutions, vector databases seamlessly integrate with popular AI frameworks and libraries. Whether it’s TensorFlow, PyTorch, or other deep learning frameworks, vector databases provide native support and APIs for seamless integration, empowering data scientists and developers to leverage the full power of AI in conjunction with vectorized data storage and retrieval.
- Semantic understanding: Gen AI models thrive on their ability to understand and generate content that resonates with human-like semantics. By harnessing the rich embeddings stored in vector databases, these models can decipher nuanced similarities and nuances within the data, paving the way for more contextually relevant outputs.
Exploring Vector Databases
- Pinecone: A cloud-based vector database known for its ease of use and focus on developer experience. It offers features like real-time updates and integrates well with popular machine learning frameworks. (Consider mentioning their focus on scaling)
Pros
- Speed and efficiency: Pinecone excels in delivering blazing-fast similarity search performance, thanks to its optimised indexing structures and GPU acceleration.
- Scalability: With its distributed architecture and seamless horizontal scaling capabilities, Pinecone offers unmatched scalability for handling large-scale Gen AI workloads.
Cons
- Limited support for complex data types: While Pinecone excels in storing and querying high-dimensional vectors, it may have limited support for complex data types beyond simple numeric vectors.
- Absence of SQL support: Pinecone lacks built-in support for SQL, the standard language for relational database management systems. This absence can present challenges when integrating with existing systems or conducting complex analytical queries that rely on SQL functionality.
- Cosmos DB: This offering from Microsoft boasts high availability and scalability, making it a good choice for enterprise-grade applications. It integrates seamlessly with other Azure services. (Highlight its managed service aspect)
Pros
- Scalability: Cosmos DB offers seamless horizontal scaling, making it suitable for handling large volumes of data, including vector embeddings.
- Schema flexibility: Cosmos DB’s flexible schema allows for storing complex data structures, including vector embeddings, without predefined schemas.
- Integrated querying: Cosmos DB supports SQL-like querying over JSON documents, enabling efficient retrieval of vector embeddings based on various criteria.
Cons
- Cost: Cosmos DB can be relatively expensive, especially for large-scale deployments or workloads with high throughput requirements.
- Indexing overhead: Managing indexing for efficient querying of vector embeddings can add overhead and complexity to the implementation.
- Azure SQL database: While not a pure vector database, Azure SQL offers extensions that enable vector capabilities. This can be a good option if you’re already invested in the Azure ecosystem.
Pros
- Integration: Azure SQL integrates seamlessly with other Azure services and tools, simplifying development and management tasks.
- Security: Azure SQL provides built-in security features, including encryption, authentication, and access control, ensuring data integrity and confidentiality.
Cons
- Scalability limitations: While Azure SQL can scale vertically, scaling horizontally for large-scale deployments may be challenging.
- Performance: For workloads with high concurrency or throughput requirements, Azure SQL may struggle to deliver the same level of performance as NoSQL or specialised databases.
- Cost: Azure SQL can become costly, especially for large databases or workloads with high resource utilisation.
- PostgreSQL: This open-source relational database can be extended with vector search functionalities through libraries like FAISS. It’s a cost-effective option for those comfortable with managing their own infrastructure.
Pros
- Reliability: PostgreSQL is known for its reliability, stability, and ACID compliance, ensuring data integrity and consistency.
- Extensibility: PostgreSQL supports a wide range of data types and extensions, allowing for flexible storage and querying of vector embeddings.
Cons
- Scalability limitations: While PostgreSQL can scale vertically, horizontal scaling for large-scale deployments may require additional complexity and effort.
- Performance: For workloads with high concurrency or throughput requirements, PostgreSQL may require careful optimisation to maintain performance.
- Cost: While PostgreSQL itself is open-source, managed PostgreSQL services on Azure may incur costs based on usage and configuration.
Remember, there’s no one-size-fits-all solution.
The best vector database for you depends on your specific needs – factors like scalability, ease of use, and integration with your existing infrastructure all play a role.
This is just a glimpse into the exciting world of vector databases. As Gen AI continues to evolve, these powerful tools will play an even more crucial role in unlocking the potential of AI to understand, create, and interact with the world around us.






