
Introduction
The term “Graph” has been around for a long time, but today it is more relevant than ever, and its importance is only growing. Graph databases are changing the way we store and explore data focusing relationships rather than individual records. It advances the way of modern application development like social networks, recommendation engines, agentic AI applications etc.
What is a Graph Database?
Before we dive into what a graph database is, let us first understand what a graph means in the world of computer science. At its core, a graph is a data structure made up of vertices and edges. Visually, you can imagine it as a set of points connected by lines. But technically, it is much more than just a picture, it is a powerful way to model and query relationships in data. A graph captures not just what entities exist, but more importantly, how they are connected. This makes it ideal for systems where the connections themselves are central to understanding the data.
A graph database is a type of NoSQL database, built for efficient storage, managing and querying graph structures. It stores the data into nodes, edges, and properties. It is optimised for relationship-heavy queries, achieving it by making relationships a first-class component of the model.
- Nodes (Vertices): These represent the entities or objects in your data. e.g., a person, a product, a place, or a document.
- Edges (Relationships): These connect nodes and describe how they are related. e.g., “Product X is part of Category Y.” Edges can be directed or undirected depending on whether the relationship has a direction.
- Properties (Attributes): Both nodes and edges can store key-value pairs of information. For example, a “User” node can have properties like name, age, and email, while a “purchased” relationship might include timestamp or price.

Why Graph Database?
For decades, RDBMS operated as the backbone for data-driven applications, organising structured data into normalised tables. Their strict schemas and tabular models perform well and are especially successful with isolated data. However, today’s interconnected digital ecosystems require more than just isolated data points; they rely on the complex, dynamic relationships that exist between them. Whether it is for real-time recommendation engines, fraud detection, or mapping complex social networks, value is often found in the connections(relationships) between data points rather than the actual data.
Types of Graphs for Modern Data Application Development
Many real-world systems like supply chain, product purchases in e-commerce and flight routes network can be modelled by graphs. There are several graphs which are suited to different applications.
| Directed Graphs | Undirected Graphs | Weighted Graphs | Hypergraphs |
| In directed graphs, edges have directions. Basically, each connection goes from one node to another in a specific order. | Edges with no direction, representing two-way relationships between nodes. | These types of graphs are useful to capture relationship strength and cost value, having weights associated with each edge. | It connects multiple nodes to a single edge. These advanced graphs can represent group relationships. |
| Recommendation enginesWeb page linksTask dependencies | Social networksCollaborative filtering | Shortest path in mapsNetwork routing | Emails sent to multiple recipients |
Two Main Graph Models
Property Graph
Property graphs are the most used, they are developer-friendly, and flexible graph models. They allow nodes and edges to have key-value pairs of attributes. Key feature for this model is it that it supports rich metadata directly on nodes and relationships. Effective for modeling complex systems.
- Nodes (Name:Jane, Age:30)
- Edges (Relationship:Friend, Since:2020)
This model is used in many modern graph databases like Neo4j, TigerGraph, Amazon Neptune (when it uses Gremlin query language).
RDF
It stands for Resource Description Framework; it comes from semantic web world and is based on simple statements called triples: Subject → Predictive → Object
E.g, Jane → knows → Doe
RDF used standard vocabulary (OWL or RDF schema), and every information is stored as a triple including metadata. No attributes on nodes or edges directly. It is commonly used where data linking, and standardisation are required most.
| Graph Type | Can it be used in Property Graphs? | Can it be used in RDF? | Notes |
| Directed Graphs | Yes | Yes | Both models support directions in relationships. |
| Undirected Graphs | Limited | Yes | RDF always treats edges as directed triples. To simulate undirected edges in RDF, you need two triplets. |
| Weighted Graphs | Yes | Yes | Both supports weights (RDF needs a bit of workaround to attach weights. |
| Hypergraphs | Limited | Limited | Both support hypergraphs with additional effort. |
Cypher Query Language – CQL
Cypher Query Language is developed for effortless querying and updating property graph databases. It was created between 2009 and 2010 and made available to the public in 2011 as Neo4j 1.3. Neo4j started out using a low-level Java API that was powerful yet complex, making it difficult for users to understand graph patterns. Cypher’s structure was influenced by SQL, but it was created to show graph patterns and use ASCII syntax to explain node and relationship patterns. Cypher has advanced over the years, offering CRUD operations, which enable complex graph manipulation and filtering.
For example, the below query conveys a person named “John” follows “Michael”.
MATCH ((j: Person{name: “John”},(m:Person{name: “Mike”}))
CREATE (j)-[:FOLLOWS] -> (m)
RETURN j, m
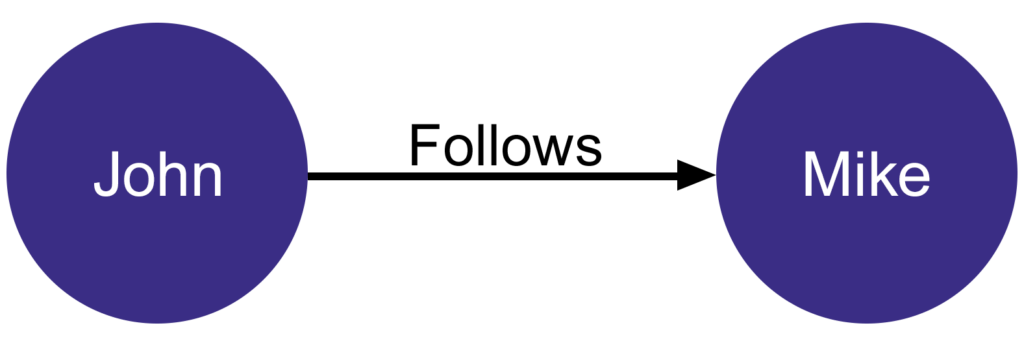
Figure 1 – Sample nodes with relationships
Neo4j started the openCypher project in 2015 with the intention of making it open source. This led to GQL, a proposed ISO standard based on Cypher. Today, Cypher has mostly replaced the Java API, which is still essential to Neo4j.
When Graph Databases are Efficient over RDBMS
Graph databases handle data as nodes (entities) and edges (relationships), with the advantage of index-free adjacency which means it allows for constant-time traversals across large datasets. Query languages such as Cypher provide flexible querying of complex data in ways that are difficult or inefficient to produce with SQL joins.
| Case | RDBMS | Graph Databases |
| Complex Joins at Scale | In a relational model, representing many-to-many relationships requires multiple JOINs across foreign keys. As the number of hops(levels) increases, query performance degrades exponentially. | It stores relationships directly in the data. Traversing connections is done in constant or near-constant time, even across multiple levels (hops). |
| Dynamic Schema | Schema changes (like adding new attributes or entity types) require ALTER TABLE, potential downtime, and data migration. This is painful in systems where the data model is constantly changing. | Graph databases use schema-optional or flexible data models to add new nodes, relationships, or properties without altering existing structures, useful for Knowledge graphs. |
| High-Connectivity Data | Relational databases optimise row-oriented data access, not interconnectivity. Modeling dense relationships between entities results in overly complex schemas (junction tables, foreign keys, etc.) | Graph DBs are designed to model and query highly connected data, allowing direct storage of relationships, making dense graphs (like logistics, telecom networks, or gene interactions). |
| Real-time Recommendations & Path Finding | Building real-time recommendation systems or finding optimal paths between entities often requires batch processing or external graph algorithms in traditional setups. | Graph DBs can do real-time traversal and graph algorithms like PageRank, shortest path, community detection, etc., as part of query execution. E.g., Real-time product recommendations, Route optimisation. |
| Recursive Queries | Recursive are hard to express in SQL and computationally expensive using Common Table Expressions (CTEs) or recursive joins. | Recursive traversal is a native operation in graph databases. Query languages like Cypher (Neo4j), Gremlin, or GQL make recursive queries simple and efficient. |
Graph Database Use Cases
Fraud Detection with Graph Database
Fraudulent transactions often hide in complex relationships, shared addresses, accounts, or phone numbers between people and businesses. Graph databases like Neo4j are designed to capture and analyse these connections. Graph databases use index-free adjacent, allowing them to explore relationships instantly, even across millions of records. This makes it easy to detect fraud rings, suspicious transaction loops, and hidden links that would otherwise go unnoticed.
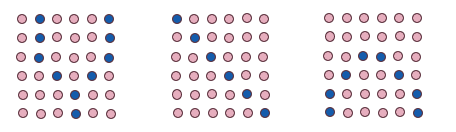
Figure 2 – Fraudulent pattern nodes illustration
Graph algorithms such as Weakly Connected Components, Node Similarity, and Pathfinding help expose fake profiles and intermediaries by tracing how entities are connected. With Cypher queries, you can quickly detect fraud patterns without rewriting complex logic, and the flexible schema makes it simple to add new data or relationship types as fraud tactics evolve. This gives teams the ability to scale detection, adapt to new threats, and stop fraud faster.

Additionally, traditional AI/ML systems, built on relational databases, struggle to detect money laundering patterns because they focus on individual transactions rather than relationships. Graph databases solve this by mapping entities like person, account, company, and their connections, which allows analysts to follow the flow of money across multiple hops and spot hidden links in large networks. Using graph algorithms like community detection, node similarity, and pathfinding, it is possible to uncover suspicious behavior that would otherwise be buried in disconnected data.
Knowledge Graphs for RAG
Vector databases are commonly used in RAG systems to retrieve semantically similar content based on user queries. However, there is no built-in way to represent relationships or hierarchies between data points. This limits their use in complex domains like healthcare or CRM, where understanding the connection between entities is critical. Knowledge graphs overcome this by modeling entities (like patients, symptoms, or treatments) as nodes and their relationships (e.g., diagnosed_with, prescribed) as edges. This allows the retrieval step in RAG to follow meaningful paths and bring back context-rich data relevant to the query.
In a knowledge-graph-powered RAG system, the model does not just search based on similarity rather it navigates a graph of connected knowledge. Metadata can be stored directly on nodes and edges (as properties), supporting advanced features like access control, data lineage, and relationship weighting. This structured retrieval provides more accurate and explainable results, enabling the AI model to generate outputs grounded in context. This approach is ideal for complex use cases like legal or medical AI, where accuracy, clarity, and reasoning are critical.
Conclusion
Graph databases are intended to handle the complexity of connected data in an easy and adaptable way. They address practical challenges that traditional databases struggle with, particularly those involving relationships and dynamic structures. As modern applications become more interconnected, the power of graph databases will only get stronger.
References
- What is a Graph Database, Neo4j Docs
- Transaction Fraud Ring, Neo4j Docs
- Using knowledge graphs to build GraphRAG applications with Amazon Bedrock and Amazon Neptune, Matheus Duarte Dias, AWS Blog Home
- A Definitive Guide to Graph Databases, by Michael Hunger, Ryan Boyd & William Lyon






